
Current applications and challenges in large language models for patient care: a systematic review

Screening results
Of the 4349 reports identified, 2991 underwent initial screening, and 126 were deemed suitable for potential inclusion and underwent full-text screening. Two articles could not be retrieved because the authors or the corresponding title and abstract could not be identified online. Following full-text screening, 35 articles were excluded, and 89 articles were included in the final review. Most studies were excluded because they targeted the wrong discipline (n = 10/35, 28.6%) or population (n = 7/35, 20%) or were not original research (n = 8/35, 22.9%) (see Supplementary Dataset file 2). For example, we evaluated a study that focused on classifying physician notes to identify patients without active bleeding who were appropriate candidates for thromboembolism prophylaxis22. Although the classification tasks may lead to patient treatment, the primary outcome was informing clinicians rather than directly forwarding this information to patients. We also reviewed a study assessing the accuracy and completeness of several LLMs when answering Methotrexate-related questions23. This study was excluded because it focused solely on the pharmacological treatment of rheumatic disease. For a detailed breakdown of the inclusion and exclusion process at each stage, please refer to the PRISMA flowchart in Fig. 1.
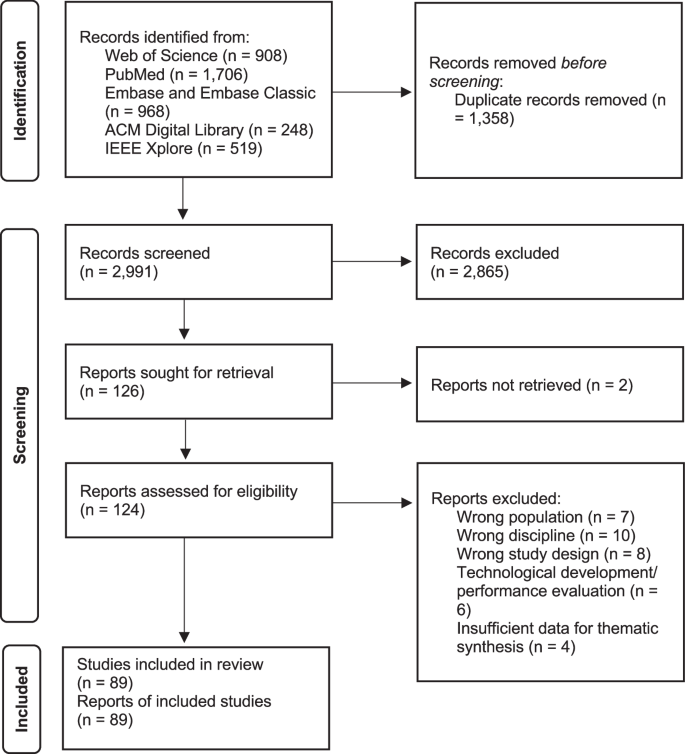
A total of 4349 reports were identified from Web of Science, PubMed, Embase/Embase Classic, ACM Digital Library, and IEEE Xplore. After excluding 1358 duplicates, 2991 underwent initial screening and 126 were deemed suitable for potential inclusion and underwent full-text screening. Two articles could not be retrieved because the authors or the corresponding title and abstract could not be identified online. After full text screening, 35 articles were excluded and 89 articles were included in the final review.
Characteristics of included studies
Supplementary Dataset file 3 summarizes the characteristics of the analyzed studies, including their setting, results, and conclusions. One study (n = 1/89, 1.1%) was published in 202224, 84 (n = 84/89, 94.4%) in 202313,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104,105,106,107, and 4 (n = 4/89, 4.5%) in 2024108,109,110,111 (all of which were peer-reviewed publications of preprints published in 2023). Most studies were quantitative non-randomized (n = 84/89, 94.4%)13,25,26,27,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,103,104,106,107,109,110,111, 4 (n = 4/89, 4.5%)28,102,105,108 had a qualitative study design, and one (n = 1/89, 1.1%)24 was quantitative randomized according to the MMAT 2018 criteria. However, the LLM outputs were often first analyzed quantitatively but followed by a qualitative analysis of certain responses. Therefore, if the primary outcome was quantitative, we considered the study design to be quantitative rather than mixed methods, resulting in the inclusion of zero mixed methods studies. The quality of the included studies was mixed (see Supplementary Dataset file 4). The authors were primarily affiliated with institutions in the United States (n = 47 of 122 different countries identified per publication, 38.5%), followed by Germany (n = 11/122, 9%), Turkey (n = 7/122, 5.7%), the United Kingdom (n = 6/122, 4.9%), China/Australia/Italy (n = 5/122, 4.1%, respectively), and 24 (n = 36/122, 29.5%) other countries. Most studies examined one or more applications based on the GPT-3.5 architecture (n = 66 of 124 different LLMs examined per study, 53.2%)13,26,27,28,29,31,32,33,34,36,37,38,39,40,42,43,44,45,46,47,48,49,52,53,54,56,57,58,59,60,61,63,65,66,67,71,72,74,75,77,78,81,82,83,84,85,86,87,88,89,91,92,94,95,97,98,99,100,102,103,104,106,107,108,109,111, followed by GPT-4 (n = 33/124, 26.6%)13,25,27,29,30,34,35,36,41,43,50,51,54,55,58,61,64,68,69,70,74,76,79,80,81,83,87,89,90,93,96,98,99,101,105, Bard (n = 10/124, 8.1%; now known as Gemini)33,48,49,55,73,74,80,87,94,99, Bing Chat (n = 7/124, 5.7%; now Microsoft Copilot)49,51,55,73,94,99,110, and other applications based on Bidirectional Encoder Representations from Transformers (BERT; n = 4/124, 3.2%)13,83,84, Large Language Model Meta-AI (LLaMA; n = 3/124, 2.4%)55, or Claude by Anthropic (n = 1/124, 0.8%)55. The majority of applications were primarily targeted at patients (n = 64 of 89 included studies, 73%)24,25,29,32,34,35,36,37,38,39,41,42,43,45,46,47,48,52,53,54,56,57,58,59,60,62,63,65,66,68,69,70,71,73,74,75,77,78,79,80,85,86,87,88,89,90,91,92,93,94,95,97,99,100,102,103,104,105,106,107,108,109,110,111 or both patients and caregivers (n = 25/89, 27%)13,26,27,28,30,31,33,40,44,49,50,51,55,61,64,67,72,76,81,82,83,84,96,98,101. Information about conflicts of interest and funding was not explicitly stated in 23 (n = 23/89, 25.8%) studies, while 48 (n = 48/89, 53.9%) reported that there were no conflicts of interest or funding. A total of 18 (n = 18/89, 20.2%) studies reported the presence of conflicts of interest and funding13,24,38,40,54,58,59,67,69,70,71,74,80,84,96,103,105,111. Most studies did not report information about the institutional review board (IRB) approval (n = 55/89, 61.8%) or deemed IRB approval unnecessary (n = 28/89, 31.5%). Six studies obtained IRB approval (n = 6/89, 6.7%)52,82,84,85,86,92.
Applications of large language models
An overview of the presence of codes for each study is provided in the Supplementary Dataset file 3. The majority of articles investigated the use and feasibility of LLMs as medical chatbots (n = 84/89, 94.4%)13,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,64,65,66,68,69,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,98,99,100,101,102,103,104,105,106,107,108,109,110,111, while fewer reports additionally or exclusively focused on the generation of patient information (n = 18/89, 20.2%)24,31,43,48,49,57,59,62,67,79,88,89,90,91,97,102,106,107, including clinical documentation such as informed consent forms (n = 5/89, 5.6%)43,67,91,97,102 and discharge instructions (n = 1/89, 1.1%)31, or translation/summarization tasks of medical texts (n = 5/89, 5.6%)24,49,57,79,89, creation of patient education materials (n = 5/89, 5.6%)48,62,90,106,107, and simplification of radiology reports (n = 2/89, 2.3%)59,88. Most reports evaluated LLMs in English (n = 88/89, 98.9%)13,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,105,106,107,108,109,110,111, followed by Arabic (n = 2/84, 2.3%)32,104, Mandarin (n = 2/84, 2.3%)36,75, and Korean or Spanish (n = 1/89, 1.1%, respectively)75. The top-five specialties studied were ophthalmology (n = 10/89, 11.2%)37,40,48,51,65,74,97,98,100,101, gastroenterology (n = 9/89, 10.1%)25,32,34,36,39,61,62,72,96, head and neck surgery/otolaryngology (n = 8/89, 9%)35,42,56,64,66,76,78,79, and radiology59,70,88,89,90,110 or plastic surgery45,47,49,102,107,108 (n = 6/89, 6.7%, respectively). A schematic illustration of the identified concepts of LLM applications in patient care is shown in Fig. 2.

A Column plot showing the distribution of medical specialties in which LLMs have been tested for patient care. B Pie chart illustrating the distribution of languages in which LLMs have been tested. C Schematic representation of the concepts identified for the application of LLMs in patient care.
Limitations of large language models
The thematic synthesis of limitations resulted in two main concepts: one related to design limitations and one related to output. Figure 3 illustrates the hierarchical tree structure and quantity of the codes derived from the thematic synthesis of limitations. Supplementary Dataset file 5 provides an overview of the taxonomy of all identified limitation concepts, including their description and examples.

The font size of each concept is shown in proportion to its frequency in the studies analyzed. Our analysis delineates two primary domains of LLM limitations: design and output. Design limitations included 6 second-order and 12 third-order codes, while output limitations included 9 second-order and 32 third-order codes.
Design limitations
In terms of design limitations, many authors noted the limitation that LLMs are not optimized for medical use (n = 46/89, 51.7%)13,26,28,34,35,37,38,39,46,49,50,54,55,56,57,58,59,61,62,65,66,68,70,71,79,80,81,83,84,85,88,91,93,94,95,96,97,98,100,101,102,103,104,105,106,107,109, including implicit knowledge/lack of clinical context (n = 13/89, 14.6%)28,39,46,66,71,79,81,83,84,85,98,103, limitations in clinical reasoning (n = 7/89, 7.9%)55,84,95,102,103,104,105, limitations in medical image processing/production (n = 5/89, 5.6%)37,55,91,106,107, and misunderstanding of medical information and terms by the model (n = 7/89, 7.9%)28,38,39,59,62,65,97. In addition, data-related limitations were identified, including limited access to data on the internet (n = 22/89, 24.7%)38,39,41,43,54,55,56,57,59,60,64,76,79,82,83,84,88,91,94,96,104,109, the undisclosed origin of training data (n = 36/89, 40.5%)25,26,29,30,32,34,36,37,40,46,47,50,51,53,54,55,56,57,58,59,60,64,65,70,71,76,82,83,91,94,95,96,101,105,109, limitations in providing, evaluating, and validating references (n = 20/89, 22.5%)45,49,54,55,56,57,65,71,73,76,80,83,85,91,94,96,98,101,103,105, and storage/processing of sensitive health information (n = 8/89, 9%)13,34,46,55,62,76,83,109. Further second-order concepts included black-box algorithms, i.e., non-explainable AI (n = 12/89, 13.5%)27,36,55,57,65,73,76,83,91,94,103,105, limited engagement and dialog capabilities (n = 10/89, 11.2%)13,27,28,37,38,51,56,66,95,103, and the inability of self-validation and correction (n = 4/89, 4.5%)61,73,74,107.
Output limitations
The evaluation of limitations in output data yielded 7 second-order codes concerning the non-reproducibility (n = 38/89, 42.7%)28,29,34,38,39,41,43,45,46,49,54,55,56,57,58,59,60,61,64,65,71,72,73,76,80,82,83,85,90,91,94,96,98,99,101,103,104,105, non-comprehensiveness (n = 78/89, 87.6%)13,25,26,28,29,30,32,33,34,35,36,37,38,39,40,41,42,43,44,46,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,64,65,67,68,69,70,71,72,73,74,75,76,77,78,79,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,100,102,103,104,105,106,107,109,110,111, incorrectness (n = 78/89, 87.6%)13,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,46,49,50,51,52,54,55,56,57,58,59,60,61,62,64,65,66,69,70,71,72,73,74,75,76,77,78,79,81,82,83,84,85,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104,105,106,107,109,110,111, (un-)safeness (n = 39/89, 43.8%)28,30,35,37,39,40,42,43,44,46,50,51,57,58,59,60,62,64,65,69,70,73,74,76,78,79,80,82,84,85,91,94,95,98,99,100,105,106,109, bias (n = 6/89, 6.7%)26,32,34,36,66,103, and the dependence of the quality of output on the prompt-/input provided (n = 27/89, 30.3%)26,27,28,34,38,41,44,46,51,52,56,68,69,70,71,72,74,76,78,79,81,82,83,90,94,95,100,101 or the environment (n = 16/89, 18%)13,34,46,49,50,51,54,58,60,72,73,88,90,93,97,109.
Non-reproducibility
For non-reproducibility, key concepts included the non-deterministic nature of the output, e.g., due to inconsistent results across multiple iterations (n = 34/89, 38.2%)28,29,34,38,39,41,43,46,58,59,60,61,72,76,82,90,94,98,99,101,103,104 and the inability to provide reliable references (n = 20/89, 22.5%)45,49,54,55,56,57,65,71,73,76,80,83,85,91,94,96,98,101,103,105.
Non-comprehensiveness
Non-comprehensiveness included nine concepts related to generic/non-personalized output (n = 34/89, 38.2%)13,28,30,34,37,38,41,43,49,51,56,57,59,61,65,70,77,79,81,84,85,86,90,94,95,100,102,103,104,105,106,107,110, incompleteness of output (n = 68/89, 76.4%)13,25,26,28,29,30,32,34,35,36,37,38,39,41,42,43,44,46,49,50,51,52,55,56,57,58,59,60,61,62,64,65,67,68,69,72,73,74,75,76,77,79,81,82,83,84,85,86,89,90,91,92,93,94,95,96,97,98,100,102,103,104,105,106,107,109,110,111, provision of information that is not standard of care (n = 24/89, 27%)28,40,43,46,49,50,54,57,58,65,69,72,73,77,78,81,85,91,94,98,100,103,107,111 and/or outdated (n = 12/89, 13.5%)13,25,32,34,38,41,43,44,49,54,83,84, and production of oversimplified (n = 10/89, 11.2%)38,46,49,54,59,79,84,85,103, superfluous (n = 16/89, 18%)13,28,34,38,46,62,72,79,86,90,94,97,100,106,107, overcautious (n = 7/89, 7.9%)13,28,37,51,70,103,110, overempathic (n = 1/89, 1.1%)13, or output with inappropriate complexity/reading level for patients (n = 22/89, 24.7%)13,34,42,48,50,51,53,55,56,67,71,78,79,85,87,88,90,93,106,107,109,110.
Incorrectness
For incorrectness, we identified 6 key concepts. Some of the incorrect information could be attributed to what is commonly known as hallucination (n = 38/89, 42.7%)25,28,32,33,35,36,37,38,40,41,42,43,44,49,50,51,57,58,59,60,65,73,74,76,77,81,83,85,91,94,96,97,98,100,103,106,107,109, i.e., the creation of entirely fictitious or false information that has no basis in the input provided or in reality (e.g., “You may be asked to avoid eating or drinking for a few hours before the scan” for a bone scan). Other instances of misinformation were more appropriately classified under alternative concepts of the original psychiatric analogy, as described in detail by Currie et al.43,112,113. These include illusion (n = 12/89, 13.5%)28,36,38,43,57,59,77,78,85,88,94,105, which is characterized by the generation of deceptive perceptions or the distortion of information by conflating similar but separate concepts (e.g., suggesting that MRI-type sounds might be experienced during standard nuclear medicine imaging), delirium (n = 34/89, 38.2%)13,26,28,30,37,43,50,58,59,61,65,70,72,73,74,75,77,79,81,82,83,84,85,90,91,92,94,95,98,102,103,107,109,110, which indicates significant gaps in vital information, resulting in a fragmented or confused understanding of a subject (e.g., omission of crucial information about caffeine cessation for stress myocardial perfusion scans), extrapolation (n = 11/89, 12.4%)43,59,65,78,81,91,94,106,107,110, which involves applying general knowledge or patterns to specific situations where they are inapplicable (e.g., advice about injection-site discomfort that is more typical of CT contrast administration), delusion (n = 14/89, 15.7%)28,30,43,50,59,65,69,73,74,78,81,94,103,111, a fixed, false belief despite contradictory evidence (e.g., inaccurate waiting times for the thyroid scan), and confabulation (n = 18/89, 20.2%)25,28,36,37,38,40,46,59,62,65,71,77,78,79,94,103,107, i.e., filling in memory or knowledge gaps with plausible but invented information (e.g., “You should drink plenty of fluids to help flush the radioactive material from your body” for a biliary system–excreted radiopharmaceutical).
Safety and bias
Many studies rated the generated output as unsafe, including misleading (n = 34/89, 38.2%)28,30,35,43,44,46,50,51,57,58,59,60,62,64,65,69,73,74,76,78,79,80,82,84,85,94,95,98,99,100,105,106,109 or even harmful content (n = 26/89, 29.2%)28,30,37,39,40,42,43,50,51,58,59,60,70,73,74,76,79,84,85,91,94,95,98,99,100,109.
A minority of reports identified biases in the output, which were related to language (n = 2/89, 2.3%)32,36, insurance status103, underserved racial groups26, or underrepresented procedures34 (n = 1/89, 1.1%, each).
Dependence on input and environment
Many authors suggested that performance was related to the prompting/input provided or the environment, i.e., depending on the evidence (n = 7/89, 7.9%)52,68,69,71,81,82,95, complexity (n = 11/89, 12.4%)28,34,44,46,70,74,76,79,94,102, specificity (n = 13/89, 14.6%)27,38,41,56,70,72,74,76,78,81,95,100,101, quantity (n = 3/89, 3.4%)26,52,74 of the input, type of conversation (n = 3/89, 3.4%)27,51,90, or the appropriateness of the output related to the target group (n = 9/89, 10.1%)46,49,51,54,72,90,93,97,109, provider/organization (n = 4/89, 4.5%)13,50,60,88, and local/national medical resources (n = 5/89, 5.6%)34,50,58,60,73.
link





